For a recent robotics project I had to run a ROS/Gazebo pipeline that was based on a pre-built x86/amd64 docker image.
I do most of my local development work on an M1 Mac. The M1 is an ARM based processor, so the question was how to get the stack to run. Unfortunately Docker for Mac was not an option, because it wouldn’t run Gazebo properly. Therefore I knew that I had to go with Linux and somewhere between the OS and the Docker I needed something (qemu or similar) to go from the x86 to the ARM instruction set.
The real breakthrough was the realization that if you use Apple’s virtualization framework to run a Linux VM you can use Rosetta (Apple’s own processor translation layer) within that VM and this this blogpost helped tremendously.
Maybe I will do a follow-up on how exactly I made it work, but the basic setup is: Debian12 in a VM (utilizing Apple Virtualization in UTM https://getutm.app) and then execute the x86/amd64 docker image with Rosetta and I am still amazed that this works.
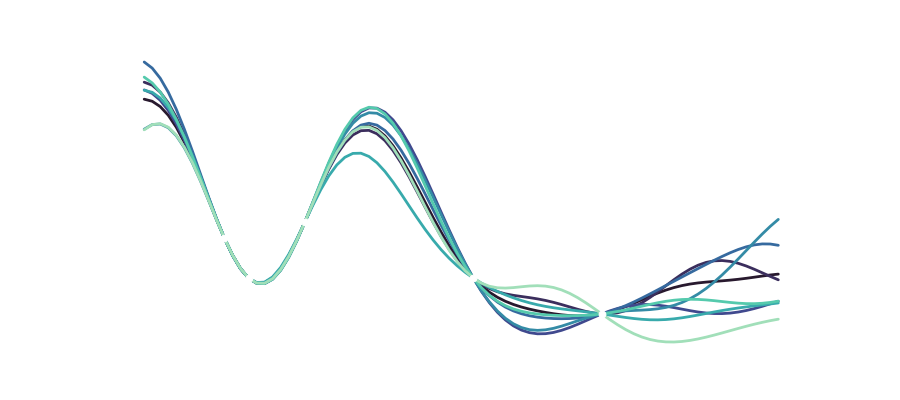
 means that for any finite batch of function values
means that for any finite batch of function values  , where
, where ![\mathbf{f} = \left[ f(\mathbf{x_1}, ..., f(\mathbf{x_n}))\right] \sim \mathcal{N}(\mu, K)](http://www.neuronenstern.com/wp-content/ql-cache/quicklatex.com-eb4f409d8ec133a700fcfcfacc948440_l3.svg "Rendered by QuickLaTeX.com") holds.
holds.![\begin{equation*} \left[ {\begin{array}{c} f \\f^* \end{array} } \right] = \mathcal{N}\left( \mu, \left[ {\begin{array}{cc} K + \sigma^2 \mathbb{I}_n & K_* \\K_*^T & K_{**} \\ \end{array} } \right] \right). \end{equation*}](http://www.neuronenstern.com/wp-content/ql-cache/quicklatex.com-cb2057e43992e88a87091fb8df55e706_l3.svg "Rendered by QuickLaTeX.com")
 part at the top left in the kernel-matrix above.
part at the top left in the kernel-matrix above.
 with
with  the lengthscale and
the lengthscale and  the signal variance. But feel free to try out another kernels, like Brownian
the signal variance. But feel free to try out another kernels, like Brownian  for example.
for example. and a variance
and a variance 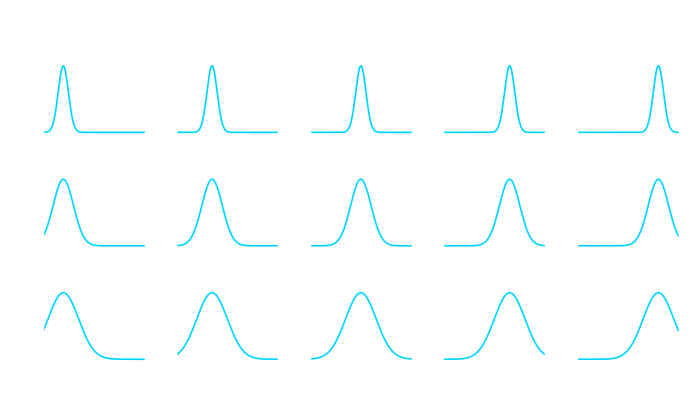
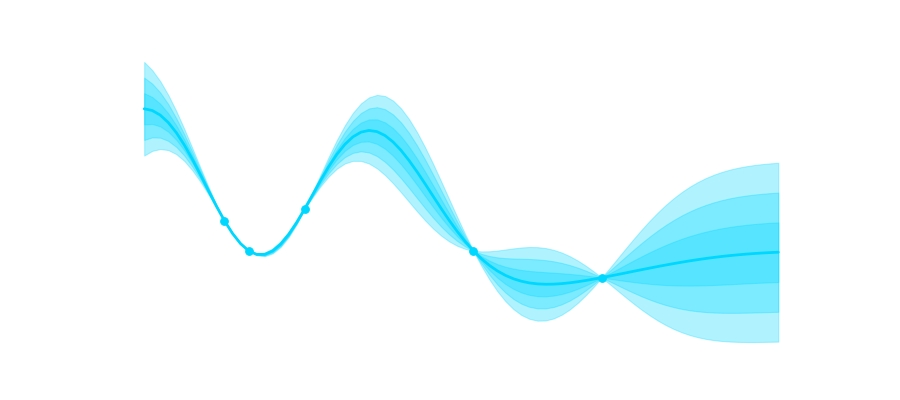
 with values
with values  ,
,  with noise in each point
with noise in each point  and points
and points  for which we want to predict the output, adapting our probability distribution leads to:
for which we want to predict the output, adapting our probability distribution leads to: , with
, with


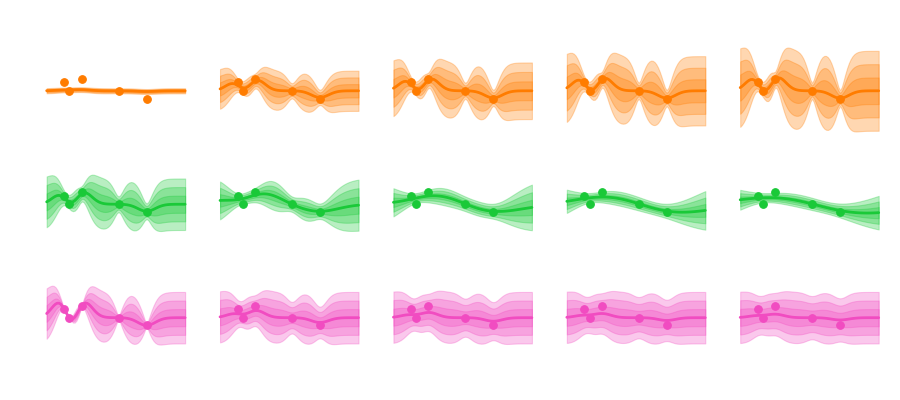
 and the noise that can influence how we model our data. Varying these parameters looks like this:
and the noise that can influence how we model our data. Varying these parameters looks like this: